
A=sum(B)
C=sum(D) を求めます。
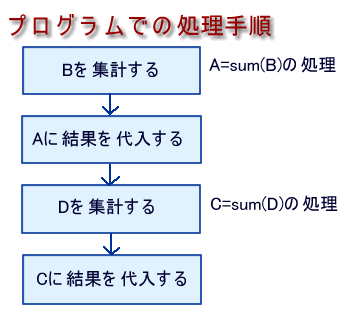
実は、AとCに結果を代入するに当たって、どちらを先に代入してもいいわけですが、同時に処理は出来ないので、プログラマは自分の好みで処理の順序を決めてプログラムを書いています。これは、たとえプログラム言語の種類が何であっても皆同じです。例えば、JAVAであってもC++であってもVBであっても、またアセンブラであても皆同じです。
データ駆動型とは、データの変更が引き金となって、それに影響を受けるデータを次々に更新をしていく方式です。したがって、今までプログラムの処理を行うプロセッサが主語で、データがそのスレーブであったのとは逆転して、データが主語となりプロセッサがスレーブとなります。つまりデータが処理を要求する形となるので、上記の2つの処理は次のようになるでしょう。
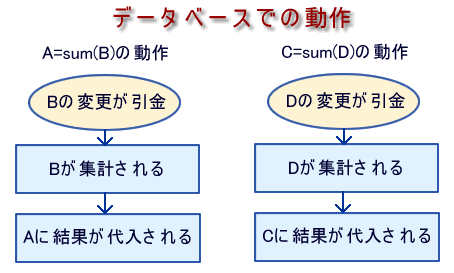
このように、Aを求めることとCを求めることは、並行して行われることになります。また、その処理の起動は、BやDのデータ値の変更がきっかけとなります。従来におけるプログラムが起動して、BやDを変更して、それらを集計してAやCに代入する形態とは逆の形態となります。
つまり、「データはそれが発生した時点で、出来る限りデータベース内で他の関連するデータに対しても即座に対応すべきである」という考え方に基づいています。
また、このような形態での定義文あるいはプログラムの記述は、各データの更新の因果関係に着目してそれぞれのデータごとに記述するだけでよくなりますので、その記述が簡潔に書けることになります。R3Dが、データのフィールド単位に導出定義文を持っているのはこの理由です。
余談ですが、これらの処理は並行して行うことができるので、もしテーブルやフィールドにプロセッサを持たせるとするならば、アレイ(配列)を並列に処理をして驚異的な処理速度をもたらすスーパコンピュータのデータベース版となることでしょう。そういう可能性をも持っているといえます。
弊社では、このように、データベースを中心にして、データの生成ロジックまでも定義する手法のことを「データベース中心主義」と呼び、「データ駆動型データベースマネージャ:R3D(Relational Data Driven Database manager)」によってそれを実現しています。
以上、データ駆動型データベースマネージャR3Dが生まれた背景について示しましたが、長年のプログラマの夢であったのかも知れません。